Building Helios: Design Choices
Choosing a Database
When evaluating storage solutions for real-time event streaming and querying, we investigated relational databases, document databases, and columnar databases. In this section we explore some of the fundamental differences between these database types.
Our criteria
High write throughput: The database must be capable of handling continuous writes of large volumes of streaming data, allowing Helios to ingest data efficiently without bottlenecks.
Low-latency query performance: Aggregating large datasets for analytical queries inherently challenges performance, and real-time analytics demands rapid insights for timely decision-making. Specifically, the database should be able to execute aggregation queries spanning multiple columns across tens of millions of rows in under a few seconds.
Extensive SQL support: Given SQL's popularity and reliability as a querying language, we prioritized databases that support a wide range of SQL features. This ensures users can leverage complex joins, filters, and aggregations, enhancing the flexibility and depth of their data analysis.
Document-based Storage
Document databases such as MongoDB and Couchbase store data in flexible, JSON-like documents. Each document can have a different structure, allowing for schema flexibility. Many document databases are designed for horizontal scaling and quick read access for contiguous pieces of data.
While document databases offer schema flexibility, we require our data to have a consistent structure, making schema flexibility a liability rather than an asset. In addition, they don’t align with our needs for high-performance analytical queries across large datasets. Please see our benchmarking section for performance metrics.
Row-based Storage
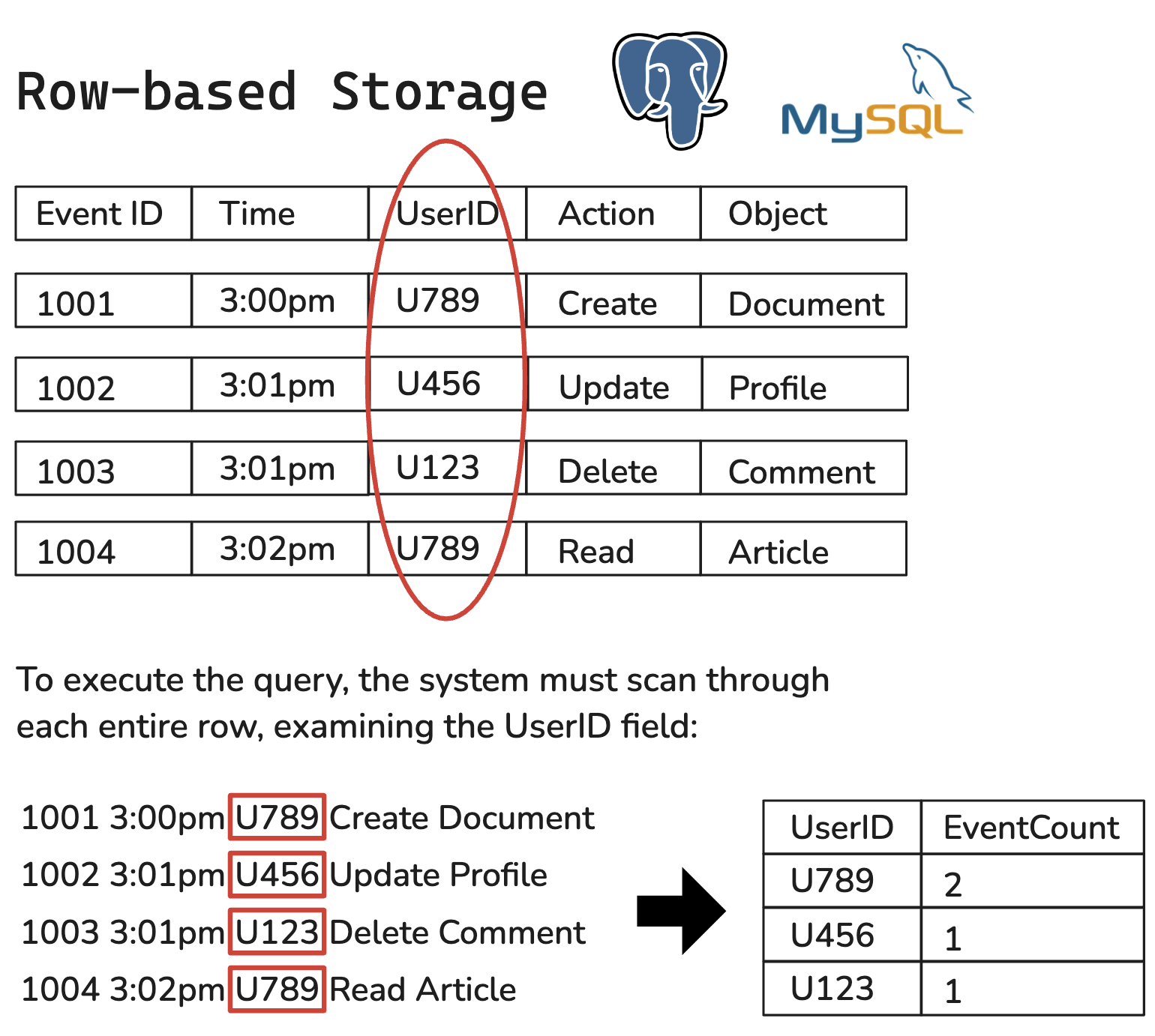
Relational databases such as Postgres and MySQL use row-based storage. It is the conventional method of storing data, where each row is treated as a primary unit and is sequentially stored on the disk. A key characteristic of row-based storage includes efficient transactions, particularly in regards to record updates and deletions.
However, row-based storage is often inefficient when it comes to analytical queries, especially those that require an aggregation of data over a few columns. In these queries, the database must read entire rows of data even when only a subset of columns are needed.
The following is a basic event table along with a basic analytic query that asks the question “How many events has each user initiated?”

Below is an example of how row-based databases might execute an analytical query:
Column-based Storage
Columnar databases such as Clickhouse and Apache Druid use column-based storage. The key difference is that columns are treated as the primary unit and stored sequentially on the disk. When running queries that span only a few columns, a columnar database can ignore unneeded columns. Additionally, columns can be compressed more efficiently than rows, leading to better storage efficiency and speed. More performance details can be found in our Benchmarking section.
Below is an example of how column-based databases might execute an analytical query:
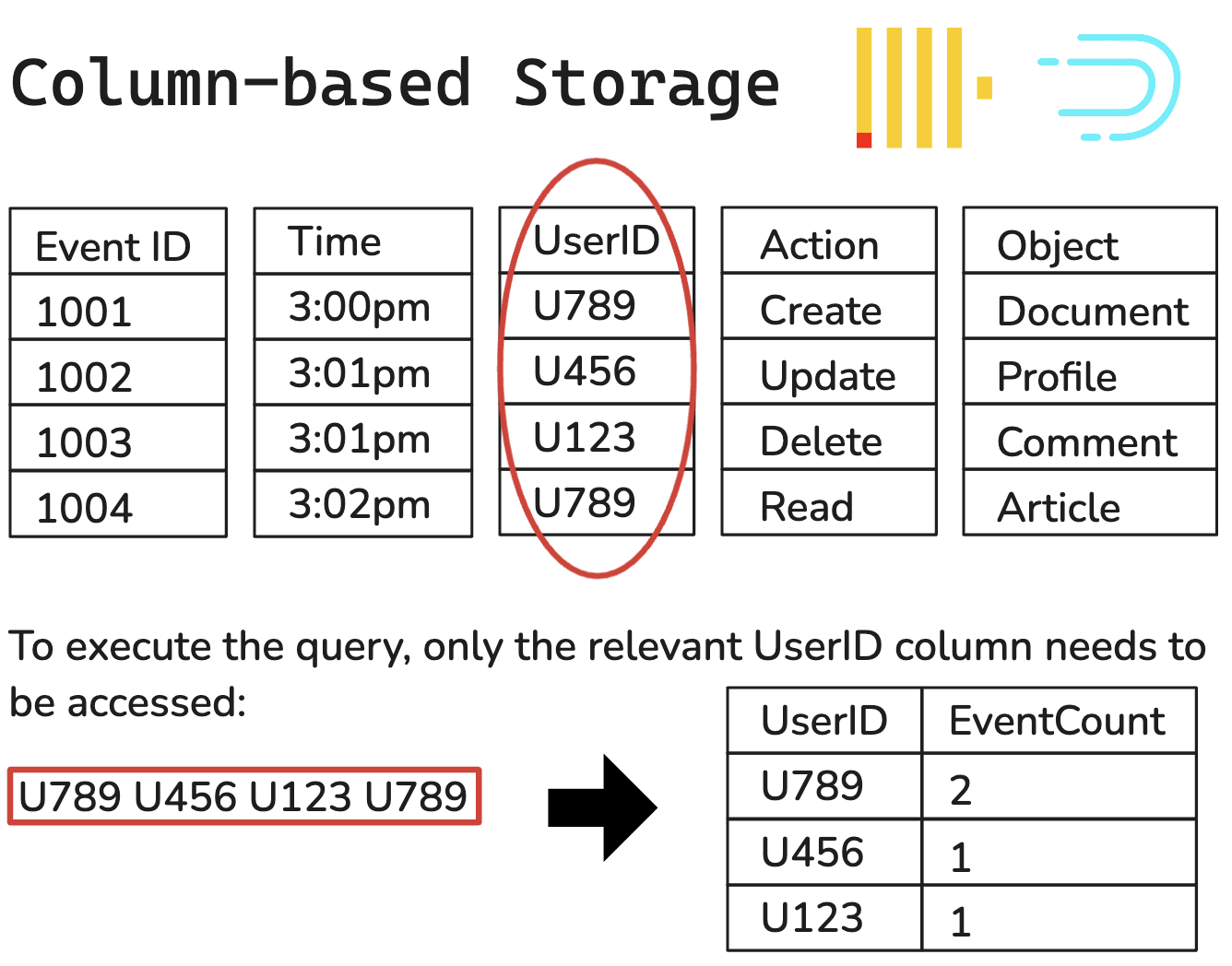
One key limitation is that the data in a columnar database is not well-suited for frequent updates or deletions of existing data. Fortunately, this drawback should not be limiting for Helios users. By nature, many real-time streaming data use-cases mostly require database reads and insertions that do not modify existing data.
After evaluating these database types, it was clear that columnar-based storage is the best fit for analytical queries.
Why Clickhouse
After deciding on a columnar database, we evaluated a number of database options and ultimately selected Clickhouse as our preferred choice because it met all of our original criteria plus had a few extra standout benefits:
High write throughput
Low-latency query performance
SQL Support
Comprehensive Documentation
Open Source
Of the criteria listed above, ClickHouse's impressive read and write latency particularly impressed us. For more insights into ClickHouse's performance, see our Load Testing results.
Deploying ClickHouse
Single Node vs Node Cluster
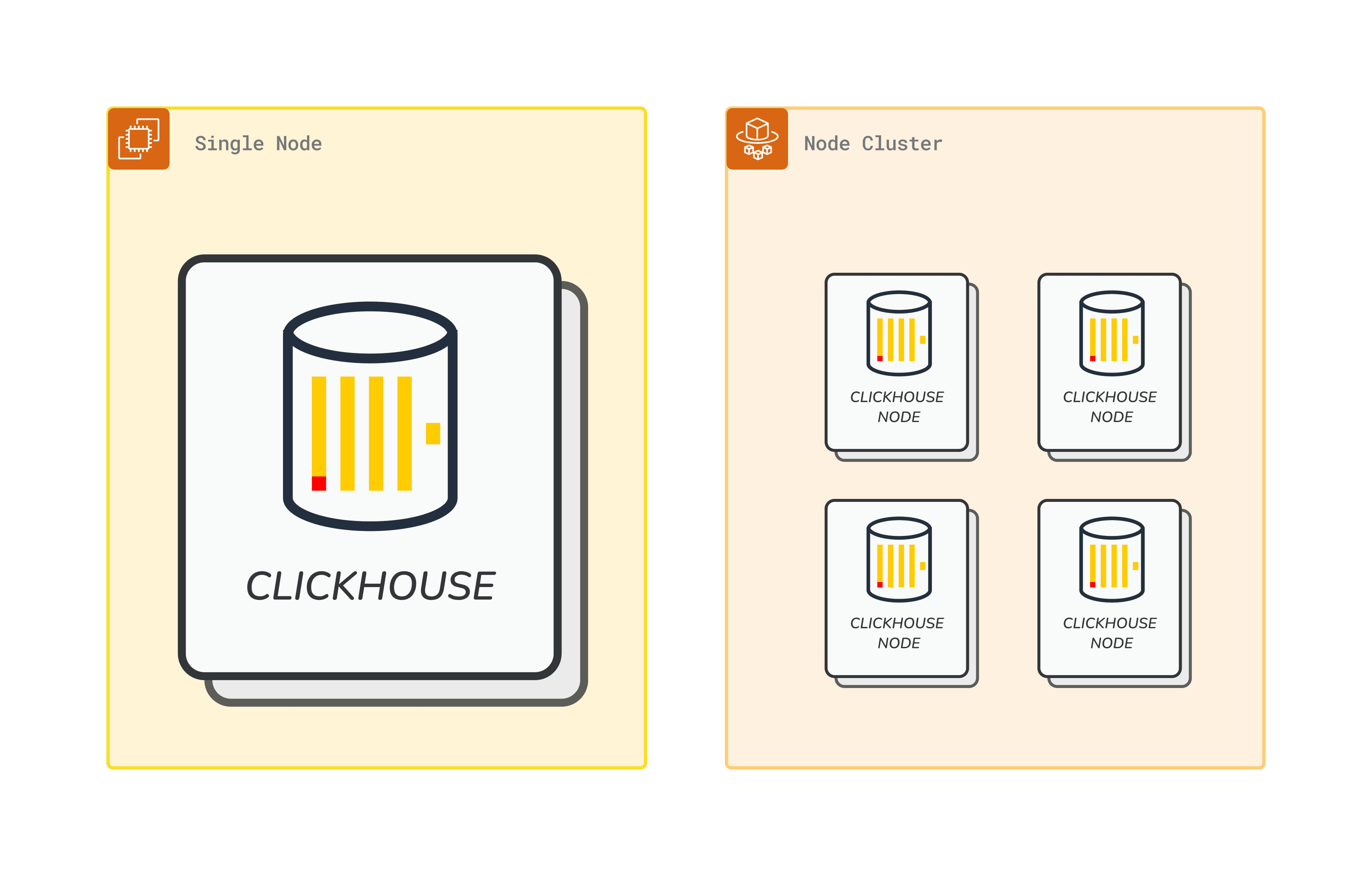
We explored several options when determining the optimal deployment strategy for the Helios production ClickHouse server. While many database deployments utilize clustered architectures for high availability and scalability, with modern implementations often leveraging containerization and orchestration tools like Kubernetes, we found this approach less suitable for ClickHouse.
Contrary to the typical horizontal scaling strategy for other database types like Druid, the ClickHouse development team specifically advises against premature horizontal scaling. Their recommendation stems from ClickHouse's design, which is optimized for efficient performance on a single server, even at scales of hundreds of billions of rows. This guidance challenged our initial assumptions about needing a containerized cluster deployment strategy.
💡 “ClickHouse was designed from the ground up to utilize the full resources of a machine. We commonly find successful deployments with ClickHouse deployed on servers with hundreds of cores, terabytes of RAM, and petabytes of disk space. Most analytical queries have a sort, filter, and aggregation stage. Each of these can be parallelized independently and will, by default, use as many threads as cores, thus utilizing the full machine resources for a query.”
Key factors in our decision-making process included:
Performance optimization: ClickHouse can efficiently handle massive datasets on a single server
Simplicity: Reduced complexity in deployment and management compared to a clustered setup.
Cost-effectiveness: Maximizing resource utilization before scaling horizontally.
Scalability: Ensuring our architecture can still accommodate future growth when necessary.
Based on these considerations, we opted to host ClickHouse on an Amazon EC2 virtual server with Elastic Block Storage (EBS). This approach allows us to leverage ClickHouse's inherent strengths while maintaining the flexibility for users to scale as needed. Later in the Scaling Helios section, we will go deeper into EBS and other vertical scaling considerations as it pertains to Helios.
Lambda Trade-offs
Cold Starts
Users of Helios may experience an initial delay when connecting their Kinesis streams, this is due to the AWS Lambda cold start. We looked into cold starts to better understand if this would have a significant impact on our user experience.
Lambda functions typically operate on a shared pool of virtual CPUs, essentially Amazon EC2 instances. When a request comes in, AWS must allocate a worker from this EC2 pool to handle it. This allocation process involves initializing the execution environment and loading a module containing the provided function code. This setup process explains why cold starts occur, introducing a brief delay before the function can begin processing the request.
This prep time setting up the execution environment, a cold start, is not charged, but it adds latency to the Lambda invocation. One could pay to ensure dedicated CPUs are available to avoid this cold start latency.

Ultimately, we decided to stick with the default setup to save users money and have our Lambda function run with cold starts versus implementing a warm Lambda. We believe that the latency impact from this initial setup is of minimal concern as per the nature of event streams; after the first execution, each Lambda execution environment will stay active as long as they are continually invoked.